

这波疫情的反扑,对不少企业业务的影响还在持续。借此机会,也让我们重新思考客户服务的含义,审视企业的核心竞争力,对客户旅程和满意度指标的检验,也从满足客户想要的,变成解决客户的迫切需求。
在危机时期进行客企互动,可能会立刻增加客户信任感和忠诚度。企业如何关怀、关心客户,并及时提供满足其新需求的体验和服务,会成为新的客户体验衡量指标。

【体验官俱乐部】前两课为各位分享了如何做好端到端的客户旅程梳理以及如何提高问卷调研的数据质量。那么当我们收到了客户的体验数据,就好比有了做菜的原料,接下来便是怎么样做出一桌好菜,那也就是怎么做数据分析和解读了。
为了帮助大家更好地用好数据这把武器,【体验官俱乐部】第三课我们再次邀请到了倍市得客户成功总监徐敏恒老师来跟大家讲讲“那些更懂你的数据模型”。
⬇️ ⬇️ ⬇️
数据模型,这是一个当下热门的词,企业非常需要那些可以通过数学模型抽丝破茧在海量数据中找到“证据”的人才,因此这也创造了很多高薪岗位。今天我们就一起聊一聊,数据模型和我们的体验管理究竟有着哪些密不可分的关联。
正式开讲前,徐老师依旧为大家推荐了一本书——《动机与人格》,这本书出自马斯洛,美国著名社会心理学家,“需求层次理论”也正是出自这本书。

人是一种不断需求的动物,除短暂的时间外,极少达到完全满足的状况,一个欲望满足后往往又会迅速地被另一个欲望所占领。人几乎总是在希望什么,这是贯穿人整个一生的特点。
在这样的特点下,对于我们企业与品牌方而言,如果我们通过各类方法收集到我们的客群声音后,是否有些什么其他方法来辅助我们明确下一个决策机会呢?
数据模型了解一下!
在第一期的直播中我们提到了如何采集一份高质量的体验数据,在我们不知道消费者下一秒会在哪出现的时候,问卷就是来采集这种广域未知客群心声的方法之一。
如何将这些采集回来的数据更好地展现在管理者的面前呢?相信很多伙伴第一印象就是可视化,通过采集后的数据,把消费者的心声汇集归拢以报表的形式展现出来。

但是我们常说数字化客户体验的内核不仅是收到这些数据,而且还要用好这些数据。数据本身没有价值,能被有效加工运用的数据才有价值。
我们期望通过这些数据去了解我们的消费者想表达什么,而不仅仅是他/她是否满意,为什么和怎么做才是核心。
CEM与问卷数据的关联性
我们通过问卷采集回来的数据分析类型一般分为三种:
- 考核类指标:NPS、CSAT满意度、费力度等等;它们往往通过环比同比等来找到某个问题的发生区域或者时间范围等等,辅助我们缩小范围。
- 算法验证类:KANO,联合分析,效度分析等;这是帮助我们挖掘数据背后含义和价值的方法,里面蕴含着百余个数据模型,我们通过数模去挖掘客户的声音,这就是好的帮手。
- AI语义分析:将文本通过AI输出情感分析与词云等。
所以通过一系列的整理我们发现想要进一步的分析我们的体验数据,可视化的下一步,数据模型是好帮手。
三个常用的数据模型
今天也为大家挑选了3个简单易懂常用的模型,帮助我们更好地理解如何通过数据模型来挖掘价值:
- 联合分析
- MaxDiff
- KANO模型
01、常用模型之联合分析
在执行联合分析时,我们一般会有以下两个基本假设:
- 消费者会购买总效用更高的产品(效用值是一个衡量受访者对产品、服务某个属性水平的偏好程度。)例如:以我们常见的餐厅满意度来说,是什么因素决定或者影响到了你的服务。
- 消费者会遵循补偿性决策过程。简单来说,产品的正面属性可以弥补负面属性,也就是客户愿意做出取舍。
# 模型的应用价值 #
联合分析,就是在有多种属性的复杂组合中,梳理出消费者选择过程中不同属性的相对重要性,以及偏好的属性组合。
举个例子
当我们想要对几款饮料的属性进行评估,我们可以先讲几种饮料的属性做一个排列组合(枚举下围绕饮料产品在口味、价格、容器和品牌)。接着去围绕这9种组合来设计一套问卷回收数据。通过联合分析对回收回来数据进行分析,我们会得到两个数值(效用值和重要性)。
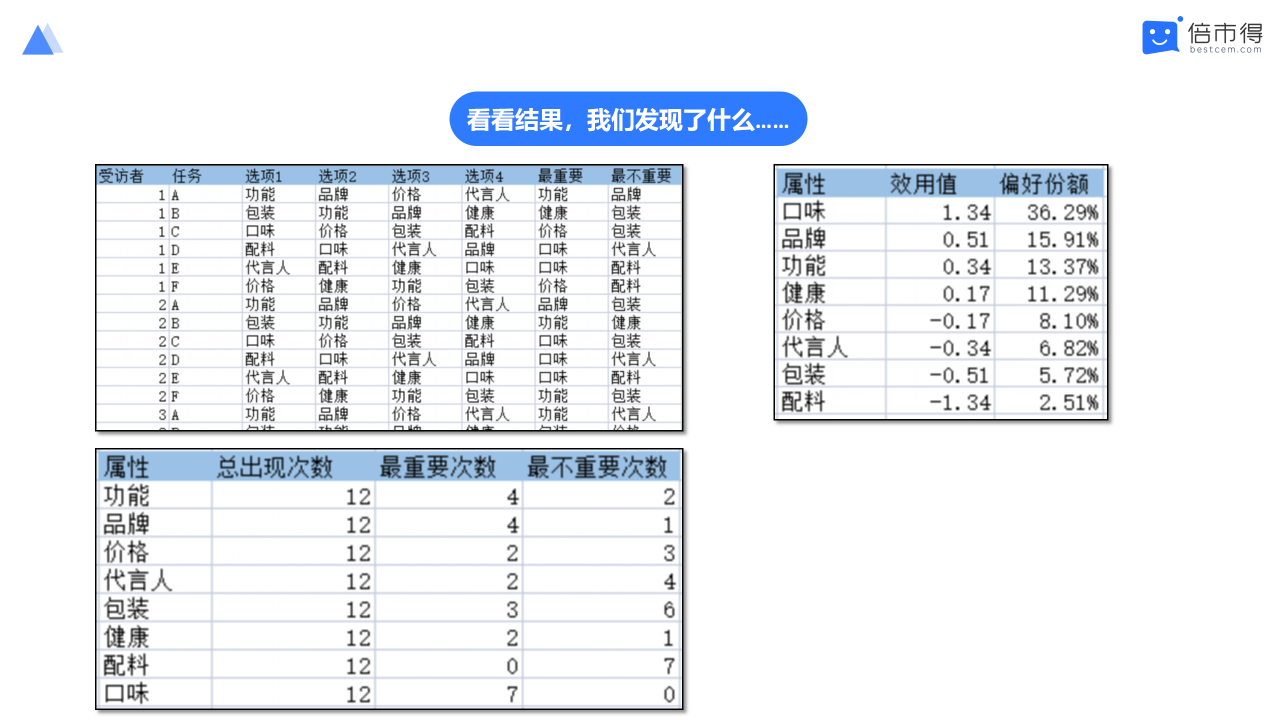
(仅为案例示意所用)
这组结果数据,我们看到容器这个属性对整款产品的影响相对更大,而且对比了下效用值,发现罐装>瓶装,人们更偏向于罐装饮料。
此外,反过来看,发现饮料的价格重要性相对更小,而且我们通过效用值可以得到大家更偏向于便宜和中等价位的饮料。
02、常用模型之MaxDiff
MaxDiff可以用来挖掘受访者对于产品属性的偏好程度。
# 模型的应用价值 #
MaxDiff (最大化差异度量)是一种市场调研的研究方法,用于了解受访者对产品属性的偏好程度。
效用值可以直观看出受访者对属性的偏好程度:值为“正”意味着该属性被选为最具吸引力的次数多于最不吸引人的次数,值为“负”意味着该属性被选为不吸引人的次数比吸引人的次数要多。
举个例子
某饮食行业品牌公司欲了解消费者对零食的偏好。一共有八个偏好对象指标,通过受试者指出“极好的”和“极差的”偏好对象,来对各产品属性的偏好程度进行评估。
通过MaxDiff分析后发现,“口味”的偏好份额值越大,更受用户重视;而“配料”的偏好份额更小,容易被用户忽略。我们需要更优先加大对产品口味的投入,来超出他们的期望。
(仅为案例示意所用)
03、常用模型之KANO模型
上面两个模型帮助我们了解消费者对产品/服务的属性偏好或重要程度,那么Kano模型则是对用户需求分类和优先排序的一个工具,为我们解决产品/服务需求和满意度之间的关系。
# 模型的应用价值 #
KANO模型的内涵,就是认为能够消除消费者不满(消除低分)和提升消费者满意(高分提升)的因素不一定是一样的。我们将其按产品服务的特性分为五类:
- 基本(必备)型 —— 客户认为产品“必须有”的属性或功能
- 期望(意愿)型 —— 是指顾客的满意状况与需求的满足程度成比例关系的需求,此类需求得到满足或表现良好的话,客户满意度会显著增加
- 兴奋(魅力)型 —— 不被顾客过分期望的需求
- 无差异型质量 —— 不论提供与否,对用户体验无影响
- 反向(逆向)型质量 —— 引起强烈不满的质量特性和导致低水平满意的质量特性

随着满足顾客期望程度的增加,顾客满意度也会急剧上升,并且一旦得到满足,即使表现并不完善,顾客的满意状况也非常高。
通过KANO的算法处理,会得到两个系数,better系数和worse系数。
Better的数值通常为正,正值越大/越接近1,则表示用户满意度提升的效果会越强,满意度上升得越快。Worse则相反,其负值越大/越接近-1,则表示对用户不满意度的影响更大,满意度降低的影响效果越强,下降得越快。在Kano模型中我们一般会最后得到一个散点图,有四个象限:
- 第一象限:better系数高,worse系数也很高。落入这一象限的属性,我们称之为是期望属性,即表示产品提供此功能,用户满意度会提升,当不提供此功能,用户满意度就会降低,这是质量的竞争性属性,应尽力去满足用户的期望型需求。提供用户喜爱的额外服务或产品功能,使其产品和服务优于竞争对手并有所不同,引导用户加强对本产品的良好印象。
- 第二象限:better系数值高,worse系数绝对值低的情况。落入这一象限的属性,称之为是魅力属性,即表示不提供此功能,用户满意度不会降低,但当提供此功能,用户满意度和忠诚度会有很大提升。
- 第三象限:better系数值低,worse系数绝对值也低的情况。落入这一象限的属性,称之为是无差异属性,即无论提供或不提供这些功能,用户满意度都不会有改变,这些功能点是用户并不在意的功能。
- 第四象限:better系数值低,worse系数绝对值高的情况。落入这一象限的属性,称之为是必备属性,即表示当产品提供此功能,用户满意度不会提升,当不提供此功能,用户满意度会大幅降低;说明落入此象限的功能是基本的功能,这些需求是用户认为我们有义务做到的事情。
通常情况下产品开发的优先级为:第四象限>第一象限>第二象限>第三象限。
举个例子
电脑应该是大家日常办公生活中常用的工具之一,厂商各显神通来满足不同细分市场和客群中的需求。那对于研发公司而言,电脑有很多种市场需求,比如:速度快、防水、外形新颖、存储空间大。
我们如果选用什么样的组合方案来回馈市场的声音以超出消费者的预期呢?

根据计算我们发现有三个属性落在第二象限,有一个属性落在第四象限。我们会针第二象限的三个属性进行优先级排序,比如要先关注防水;杯子里水翻了我们的文档别没了。
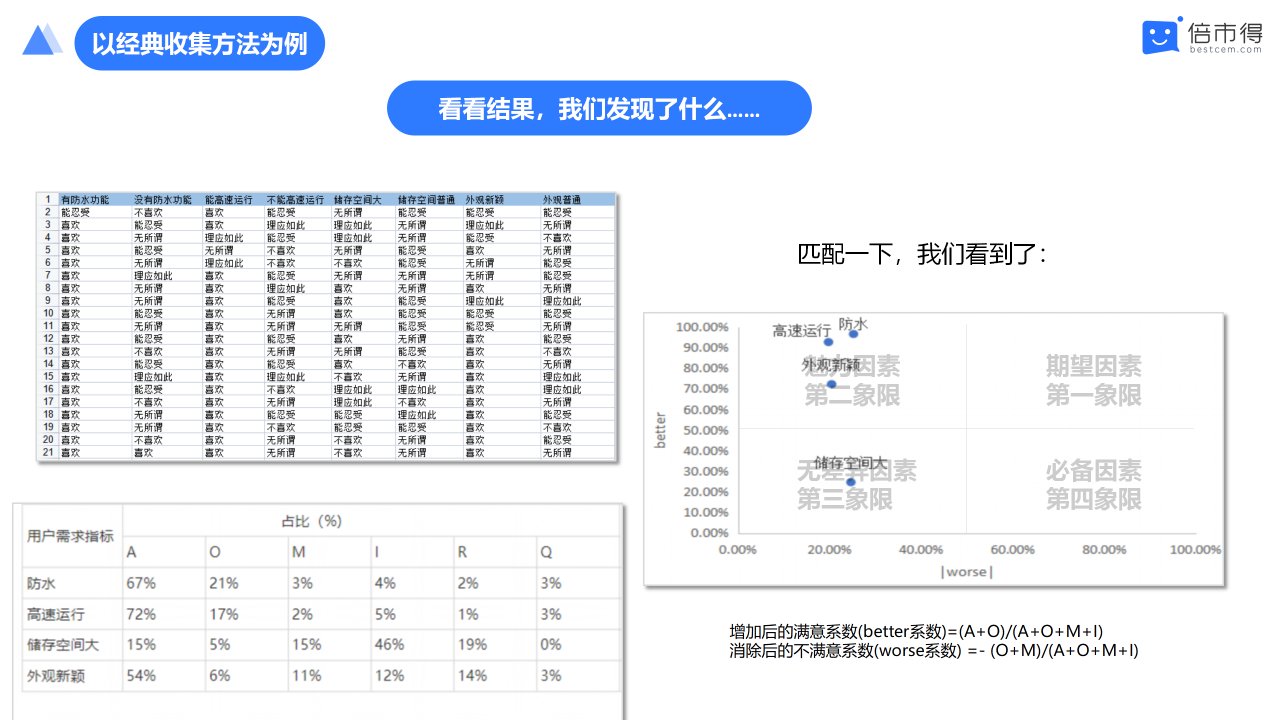
仅为案例示意所用
总结
- 联合分析,可以在服务项中找到影响体验的重要要素;
- MaxDiff,可以通过分析了解消费者的偏好;
- 而KANO可以对需求和满意度进行结合,找到更优解决/实现的功能来满足消费者。
我们不要只关注事后的投诉处理,应该通过数据和我们的经验在更前面的阶段满足我们的消费者,用好的办法帮助我们提升消费者的提升以驱动增长。
学会这些方法,让增长持续下去。
