

净推荐值(NPS)是大多数面向客户的行业中公认的客户忠诚度衡量标准。我们利用NPS来衡量Airbnb为其客人和房东提供的服务满意度程度如何。
但是NPS有两个主要的问题:
NPS是零散的,因为只有有限的用户对调查做出了回应,
NPS反馈很慢,结果显示至少需要一周时间。
Airbnb在核心产品和客户服务产品中大量使用A/B测试。在A/B测试领域,查看结果和解释结果所需的时间越长,迭代客户服务质量所需的时间就越长。这就是为什么我们需要一个更加敏感和稳健的指标。
为了解决这些限制问题,Airbnb开发了一种基于AI的情感模型来补充NPS。情感模型可以处理用户发送给CS(客户支持)代表的消息,以提取反映用户情感的信号。与NPS相比,情感模型评分具有以下优势:
更高的覆盖率:可以不局限于提交调查问卷的人,因此在调查过程中有Airbnb更多的注册用户可以被纳入进来;
更好的灵敏度:在进行试验时,达到统计显着性所需的时间要少得多;
与长期客户忠诚度的因果关系:我们可以将用户情绪分数“转化”为长期业务价值。
本文提供了有关我们如何开发情绪模型和聚合原始情绪分数来衡量客户情绪的相关见解。我们利用熵平衡(Hainmueller,2012)创建了一个反事实组,以检测情绪指标与未来收入之间的关系。根据我们的研究,我们展示了情感模型与NPS相比更出色的表现。
情感模型开发
情感分析是一个衡量消费者对特定产品或服感受的好方法。在Airbnb的客户支持中,来自房客和房东的情绪是我们打造更好产品和服务并考虑到社区的变化的重要信号。
在客户支持领域开发情感模型时,我们面临两个主要挑战。
倾斜数据:大多数留下文字的情绪都是负面的。与给房东留下评价或消息不同的是,房客在遇到Airbnb的问题时通常会联系客户支持团队。
多语言输入:Airbnb的客户服务支持超过14种语言。房东和客人可能在同一张支持票中使用不同的语言进行交流。
为了构建适合Airbnb使用的情感模型,我们为客户支持消息定制了评级指南,以方便我们的模型了解特定领域的知识和上下文信息。
下面的示例说明了同一条消息在CS消息与社交媒体帖子或App Store评论呈现时是如何被打上不同标签的。在CS领域,我们关注客户“认为”问题作为问题解决程度是积极的迹象,以及他们“感觉”问题作为消极迹象的程度。
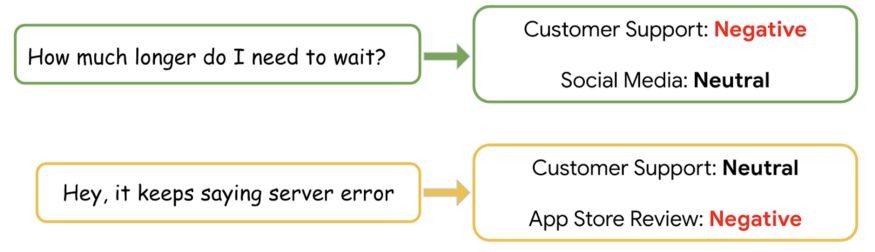
我们通过使用ML模型对人工注释过的采样数据进行多次迭代,并使用新标记的数据重新训练模型来解决数据偏差问题。第一轮标注基于随机抽样进行,后续标注数据集根据现有模型预测进行分层。这就为训练提供了一个更加平衡的数据集。
我们构建并测试了两种深度学习架构,都支持多语言推理:
WIDeText使用基于CNN的架构来处理文本通道,而所有分类特征都通过WIDe通道处理。
XLM-Roberta使用基于转换器的架构并利用预训练的多语言模型来训练CS消息以14种语言进行训练。
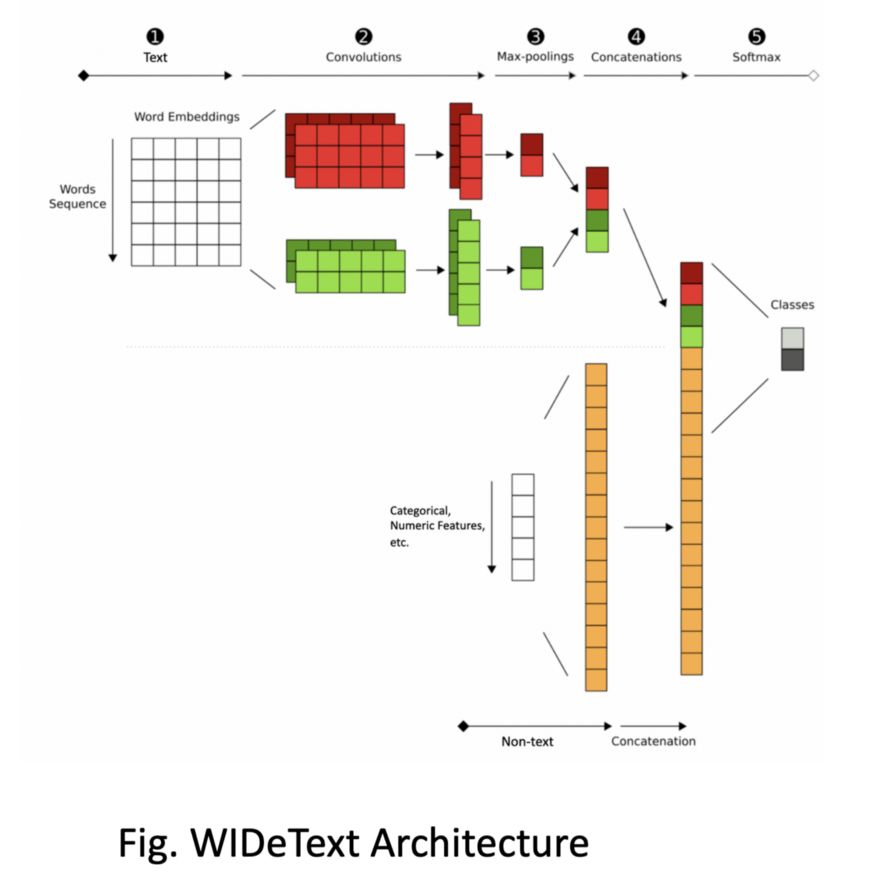
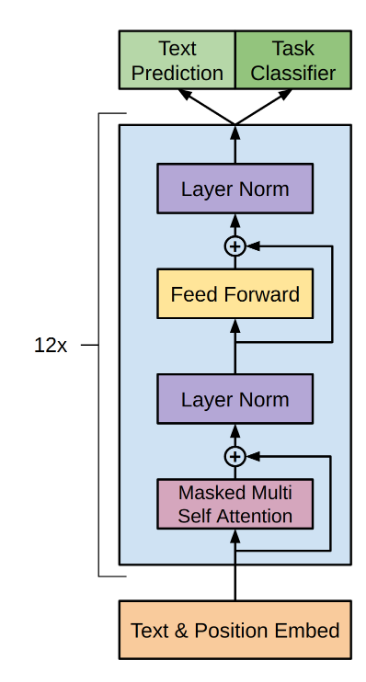
WIDeText体系结构Transformer Architecture
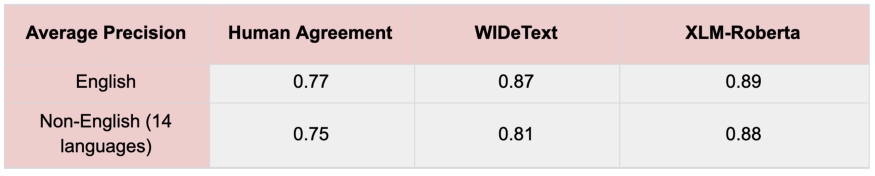
基于Transformer的模型在英语情感分析上的表现稍好一些,在不太常用的语言上表现得更好。
情绪指标开发
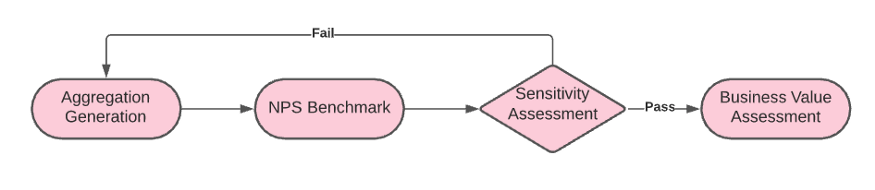
根据原始情绪分数,我们开发了情绪指标,旨在优化以下标准:
- 与NPS的强相关性
- 实验灵敏度
- 与长期业务收益有可证明的因果关系
与NPS的相关性
尽管NPS存在局限性,但它仍然被认为是用户情感分析的黄金标准。为了保证情绪模型指标与NPS有很好的相关性。我们通过聚合消息级原始情绪分数(例如,均值、截止值、斜率)以与NPS相关联,测试了设计指标的各种方法。
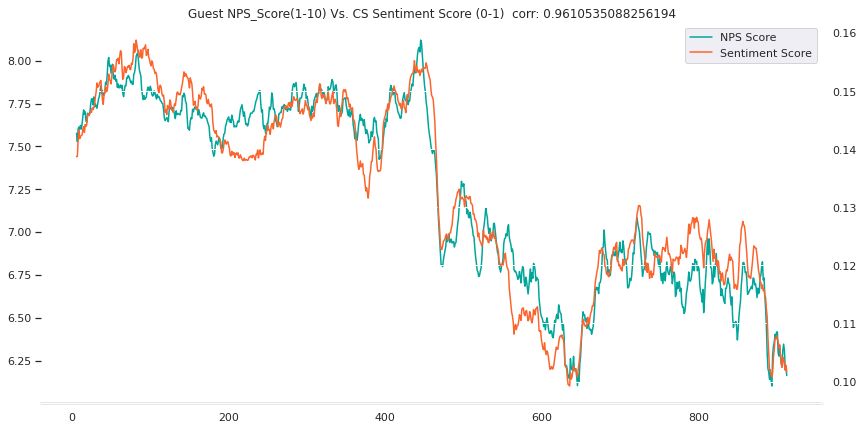
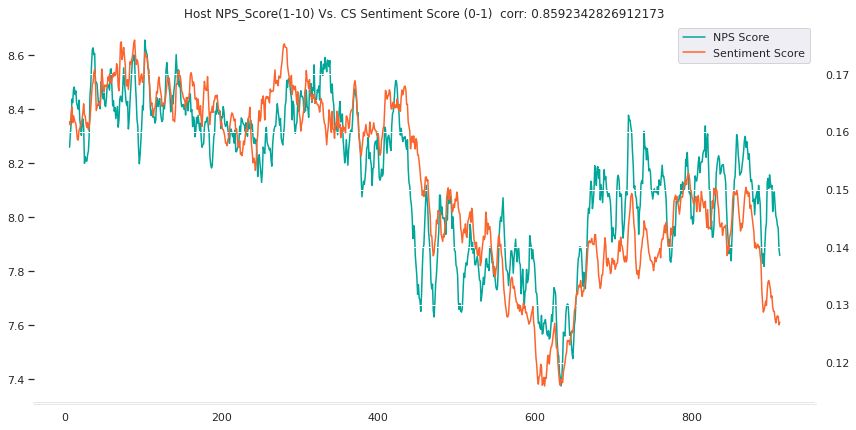
下面的两个图表说明了情绪得分和NPS得分在客人和房东情绪上的相关性很好。
客人样本上的NPS(绿色)与情感指标(橙色)房东样本上的NPS(绿色)与情绪指标(橙色)
实验灵敏度
我们重新审视了过去的两种类型的实验(场景1和2),来比较NPS和情感模型之间的实验敏感性。目标是确定情绪指标是否可以提供更快或更准确的反馈以响应用户情绪的变化。
场景一
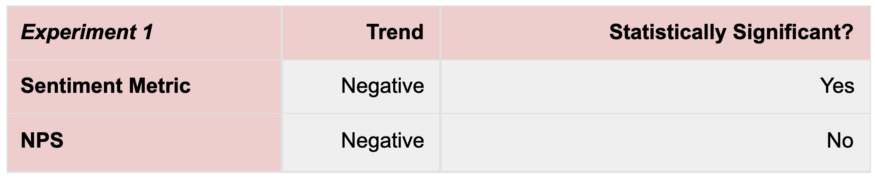
在第一类实验中,一个新的产品/服务功能损害了用户研究中的用户体验(例如,服务需要额外的步骤来联系支持代理),但这些功能在NPS中没有显示出任何统计上的显着变化。
例如,在我们的一项交互式语音响应(IVR)实验中,我们通过向我们的自动电话消息系统添加更多问题成功地降低了联系率。然而,这也增加了试图获得客户支持还是没有呈现显著性统计。
当我们将情感指标应用于此实验时,我们能够在5天后检测到新情感指标的变化达到了统计显着性。
场景二
第二种类型的实验在产品/服务中具有损害用户体验的特性,并且确实以统计显着的方式影响了NPS。例如,我们的一个聊天机器人实验降低了NPS和情绪指标,但NPS在第10天达到统计显著性,而情绪指标收敛得更快,在第5天就检测到变化。

与长期客户忠诚度的关系
作为一个低频市场,Airbnb实验框架的挑战之一是难以评估长期客户忠诚度,例如产品迭代中的用户流失率和未来预订收入。对于客户支持团队来说,我们的产品对用户体验的影响尤其大。实验应该帮助决策者回答“如果一个产品/服务功能降低了成本但损害用户满意度,我们是否应该推出产品/服务功能?”的问题。
我们的第三次评估使用情绪评分指标量化客户服务对未来预订的影响。
使用两个不同的代理池运行A/B测试将是非常昂贵的,这些代理池为不同的用户组提供不同的服务标准。相反,我们使用一种新颖的因果推理技术,通过观察数据来检测情绪对用户未来一年预订收入的影响。
我们将用户分为两组:控制组,具有相对较低的情绪分数,以及处理组,具有更高、更积极的情绪。我们需要控制这样一个事实,即这两个群体可能在许多方面存在根本差异,例如他们对不同服务质量水平的容忍度、对我们平台的忠诚度以及历史预订经验。
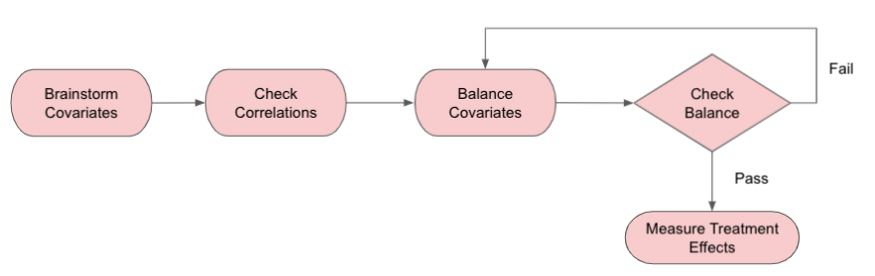
建立情感评分与未来收入关系的分析工作流程
为了评估提供良好客户服务的更可靠的长期影响,我们建立了一个程序:
- 找出混杂因素,
- 使用熵平衡控制这些协变量,
- 使用加权数据评估效果。
- 混淆变量选择
在我们能够缩小适当的混淆变量并生成协变量矩阵之前,我们进行了几轮迭代。我们列出了应该考虑的所有可能的混淆变量。这涵盖了多个学科,包括用户帐户信息、以前的预订行为、客户联系习惯等。然后我们选择了与情绪和未来预订相关的相关变量。例如,以前预订较多的用户往往会预订更多,并且在与客户支持代理沟通时更积极。最后,我们交叉检查所有变量之间的相关性以去除多余的变量。这帮助我们选择了一个简短的混淆变量列表。

熵平衡
我们使用熵平衡来实现协变量平衡。熵平衡是一种最大熵重新加权方案,用于创建满足一组约束的平衡样本。以下是该计划中两个最重要的功能:
1. 协变量分布的均衡矩。通过为每个样本单元分配权重wi,我们希望处理组和重新加权的对照组之间的协变量分布的矩(例如,均值、方差和偏度)相等(在等式2中定义)。一个典型的平衡约束用包含来自治疗组的给定变量Xj的rthorder矩的mr公式化,而对控制组的矩函数指定为cri(Xij)
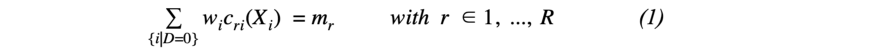
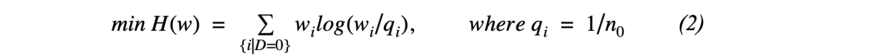
它擅长平衡高阶矩的结果。大多数其他预处理方法涉及对模型和匹配进行多轮手动调整直到达到平衡结果(在高维样本上经常失败),熵平衡直接搜索可以在有限样本中实现精确协变量平衡的权重。它显着改善了可以通过其他方法获得的平衡,这些方法得到了保险用例Matschinger(2019)的验证。
它保留有价值的信息而不丢弃单位。熵平衡通过允许单位权重在单位之间平滑变化来保留有价值的信息,因此我们不必丢弃任何不匹配的数据。
它用途广泛。我们得到的权重几乎可以用于任何标准的处理效果估计,例如加权平均和加权回归。
它的计算成本很低。只需几秒钟即可获得超过100万条记录的平衡结果。
评估处理效果
在使用熵重新加权后,我们能够针对所有混淆变量获得平衡的结果:

通过加权结果,我们发现Airbnb上情绪较高的客人(情绪指标>=0.1的潜在良好CS体验)在随后的12个月内产生了显着更多的复购。每当我们在成本和用户CS情绪评分中看到相反的结果时,就可以将此结果应用于权衡分析,并帮助我们在考虑长期收入的情况下做出正确的发布决策。
在这篇博文中,我们提供了情感模型开发的详细信息和评估情感指标的框架。
对于ML从业者来说,情感分析的成功取决于特定领域的数据和注释指南。我们的实验表明,基于transformer-based比基于CNN-based表现更好,尤其是在不太常用的语言中。
对于在NPS痛苦中挣扎的客户服务提供商,情绪分析提供了可喜的结果来描述客户的满意度。如果你有用户交流文本,探索情感分析可能会解决NPS长期存在的痛苦。但是,如果您只有电话录音,在探索音频中的情绪检测之前,探索音频到文本的转录可能是一个好的开始。
对于数据分析师和数据科学家来说,基于新信号(模型输出)的指标开发框架是可重用的:考虑到许多用户反馈指标要么缓慢要么稀疏,数据专业人员可以从覆盖范围、敏感性和因果关系评估新信号与商业价值。对于因果分析挑战,值得花一些时间探索新的熵平衡技术,这可能会节省您进行倾向得分匹配的时间。
原文作者:Shuai Shao,Mia Zhao,Yuanyuan Ni,由倍市得编译整理
倍市得——数字化体验管理,助你倍市可得
